ChatGPT 與 LLM 的技術原理剖析、發展歷程


LLM
ChatGPT 作為當前自然語言處理領域的熱門技術之一,其模型設計和性能優異程度深受廣大研究者和應用開發者的青睞。本文將對 ChatGPT 的技術原理進行剖析,介紹其背後的深度學習技術和演算法,同時分析其發展歷程及其在自然語言處理領域的應用。
三個關鍵背景知識
要探討 ChatGPT 的技術原理,有三個關鍵背景知識我們需要先建立:
- 神經網路與深度學習
- 大型語言模型 LLM
- 生成式 AI
算力的增加讓 AI 神經網路再度復甦
人工智慧(AI)的歷史可以追溯到上世紀五十年代,當時,科學家們開始設計能夠模擬人類智能的機器,嘗試實現機器能夠像人一樣進行推理、學習、問答等任務。
神經網路最早起源於上世紀五六十年代,並且曾經在八十年代和九十年代得到了廣泛的關注。但是,當時的計算資源和資料量有限,神經網路無法發揮出其潛力,在此過程中,AI 技術經歷了多個階段的發展,從最初的符號邏輯推理到基於規則的專家系統,再到統計學習的機器學習。
隨著資料量和計算資源的不斷增加,神經網路在二十一世紀初逐漸復興,2006 年,深度學習(Deep Learning)的代表性模型之一 —— 深度信念網路(Deep Belief Network,DBN)被提出,為深度學習的發展奠定了基礎。之後,卷積神經網路(Convolutional Neural Network,CNN)在圖像識別等領域取得了重大突破,進一步推動了深度學習的發展。
AlphaGo 於 2016 年擊敗人類頂尖棋手李世石,展現了深度學習在人工智慧領域的強大潛力,並且引起了廣泛的關注。此後,深度學習在圖像識別、自然語言處理、語音識別等領域取得了許多成功的應用,成為當今人工智慧領域最重要的技術之一。
大型語言模型(LLM)的出現,應用於自然語言處理(NLP)
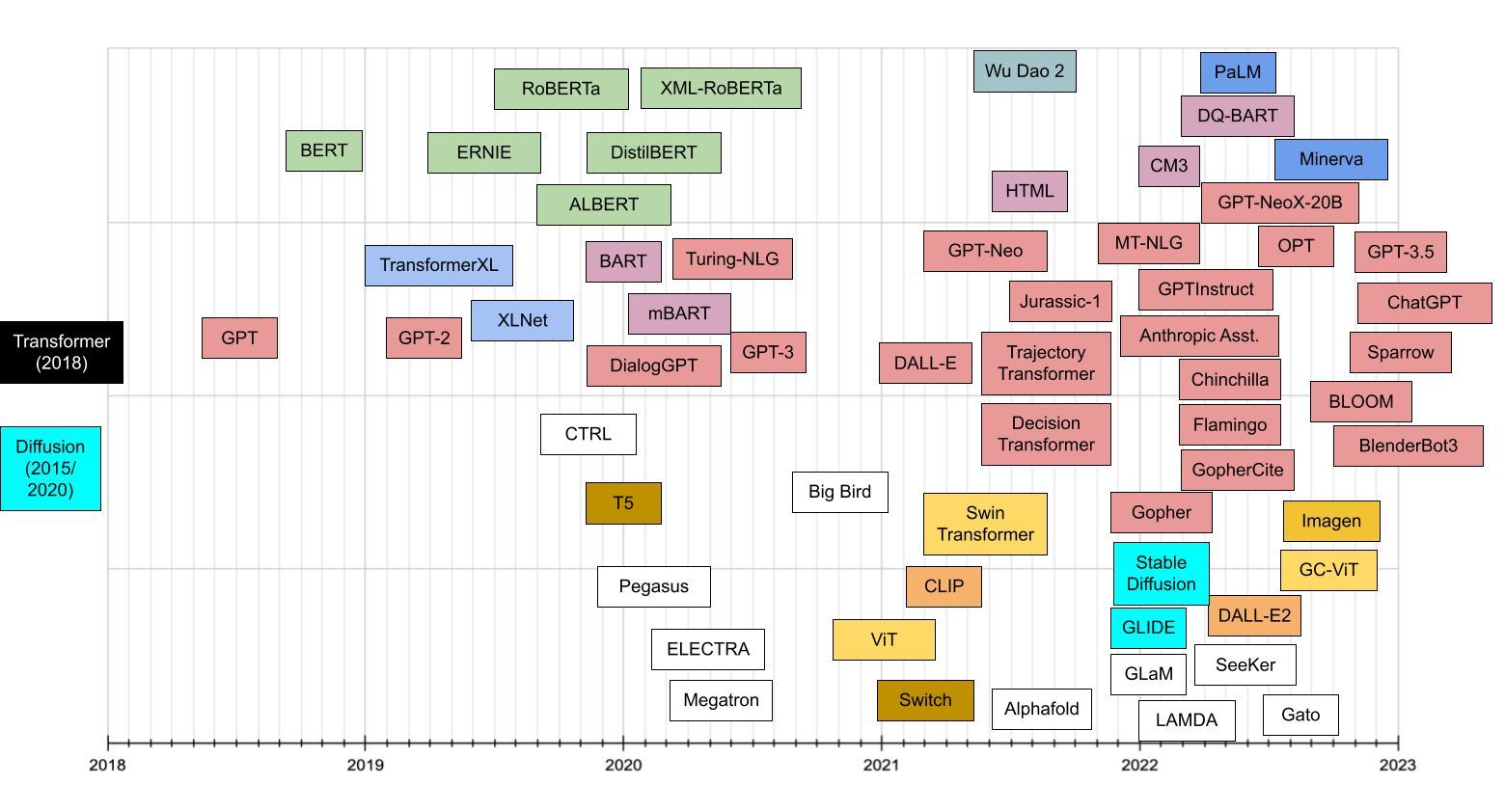
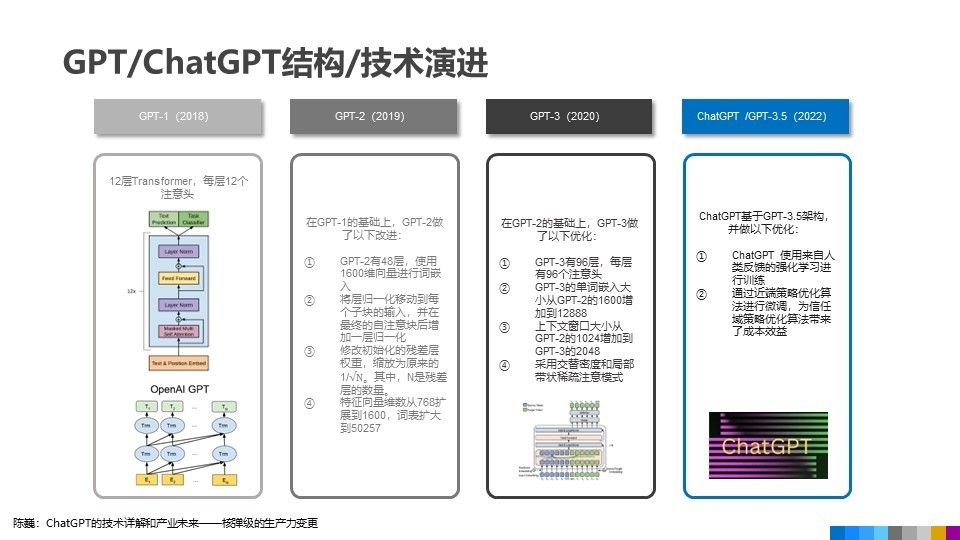
2018 年是自然語言處理模型取得大規模突破的重要時刻,由於深度學習技術的快速發展和大量文字資料的普及,LLM 已經成為自然語言處理領域的一個熱門研究方向,當時 Google 和 OpenAI 分別提出了 BERT 和 GPT 等基於深度學習的自然語言處理模型,這些模型通常具有數十億到數千億個參數。
- BERT 是一種雙向編碼器,能夠同時考慮上下文中的單詞
- GPT 則是一種單向解碼器,只能看到上文的單詞。
這兩種模型都在多項自然語言處理任務中取得了當時最好的效果,並且被廣泛應用於搜尋引擎、語音識別、機器翻譯、問答系統等領域。
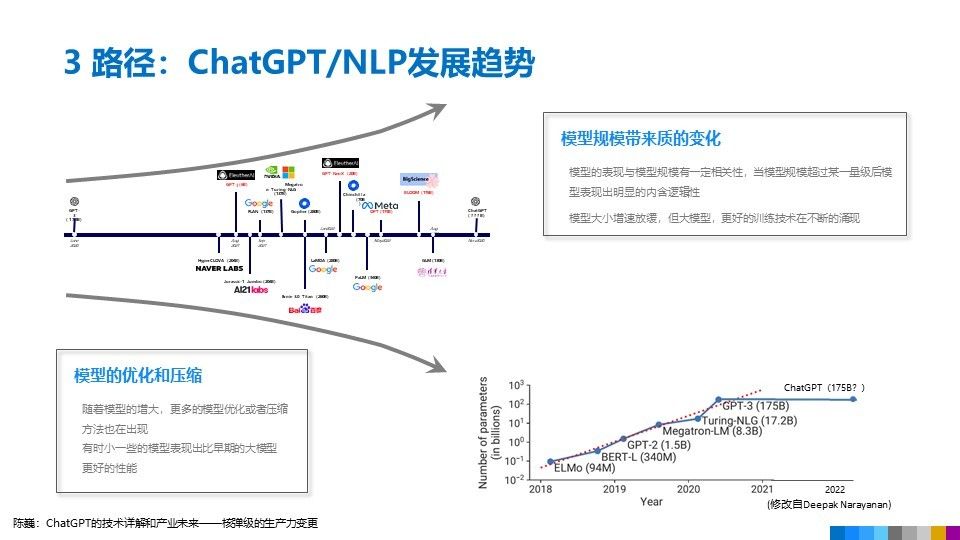
2019 年,Google 提出了 BERT 的改進版 ——RoBERTa,進一步提升了模型的性能。2020 年,GPT-3 模型被推出,成為當時最大的自然語言處理模型,其能力已足以生成實際上無法區分的人類文字。
生成式 AI(Generative AI)不再依賴人工標記
LLM 之一的 GPT(Generative Pre-training Transformer)模型屬於生成式 AI(Generative AI),可以生成自己的輸出,不需要大量的樣本資料或人工設計的特徵。
GPT 模型是一種基於 Transformer 模型的語言模型,其訓練方式分為預訓練和微調兩個階段:
- ** 預訓練階段 **:GPT 使用大量未標記的文字資料,透過自監督的方式進行訓練,學習到了自然語言的語法、詞彙和上下文等特徵。具體來說,GPT 的訓練方式是透過預測下一個單詞的方式進行的,因此它可以從大量未標記的文字中自動學習到單詞之間的語義和語法關係,而不需要人工標記。
- ** 微調階段 **:GPT 可以使用少量標記的資料進行微調,以適應特定的自然語言處理任務。在進行微調時,GPT 使用已經學習到的上下文語言模型,從而更好地理解上下文,並且可以根據上下文生成新的文字,具有很好的生成能力。
GPT 的主要特點是它可以從未標記的大量文字資料中自動學習到自然語言的語法、詞彙和上下文等特徵。這種自監督的訓練方式不需要人工標記,使得 GPT 的訓練成本大大降低,並且可以更好地應對多樣化的自然語言處理任務。這種技術在自然語言生成、圖像生成、音頻生成等方面都取得了很好的效果。
LLM 技術上的能力限制
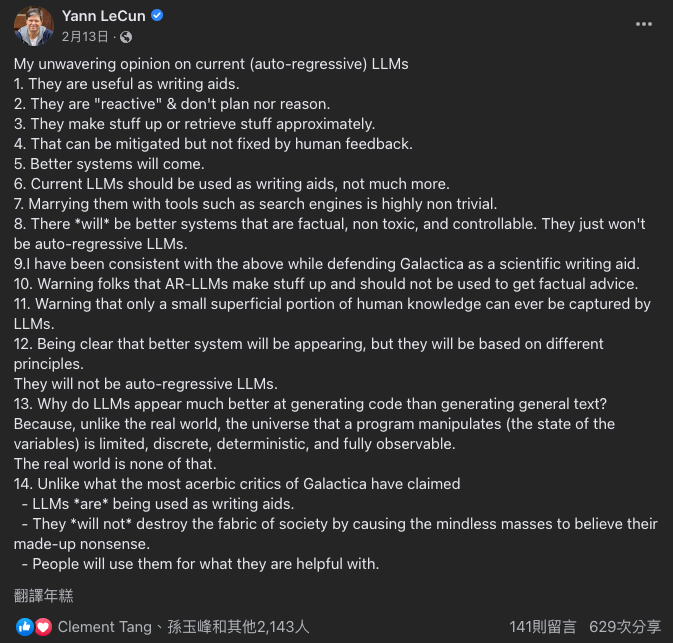
Yann LeCun 是一位著名的計算機科學家和人工智慧專家,他被譽為深度學習的開創者之一。他於 2013 年獲得了圖靈獎,這是計算機科學領域最高的榮譽之一,以表彰他對深度學習的開創性貢獻。LeCun 在紐約大學擔任教授,並且是 Facebook 人工智慧研究院的首席 AI 科學家。
在 ChatGPT 興起一股旋風之後,Yann 在 FB 發表了他對 LLM 的看法,認為 LLM 對於寫作有用,但它們沒有計劃或推理能力,會隨意編造,雖然人類的反饋可以減輕這種問題,但無法從根本上解決這個問題,並呼籲警惕使用 LLM 以獲取真實的建議,並且提醒人們 LLM 只能捕捉人類知識的表面部分,因為程式碼操縱的宇宙(變量的狀態)是有限的、離散的、可確定的和完全可觀察的,而現實世界則不是這樣的,他強調 LLM 適合應用在寫作輔助,而不是其他用途。
LLM 還可以做什麼?
- Large Language Models and Where to Use Them: Part 1
- Large Language Models and Where to Use Them: Part 2
ChatGPT 是如何煉成的?
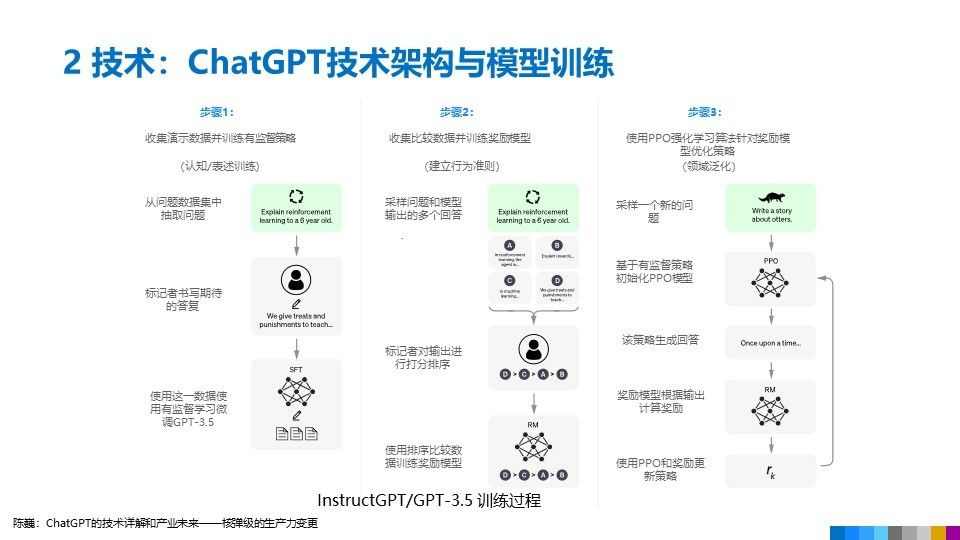
第一階段:訓練監督策略模型
在 ChatGPT 學習的初期階段,它必須學會如何生成有意義的語句,而文字接龍是一種很好的練習方法。文字接龍是指從一個詞彙開始,生成一個與該詞彙相關的詞彙,並以此為基礎繼續生成詞彙。透過不斷練習,ChatGPT 可以更好地理解語言結構和詞彙之間的關係,從而產生更流暢、更自然的語句。
與 BERT 模型類似,ChatGPT 或 GPT-3.5 都是根據輸入語句,根據語言 / 語料概率來自動生成回答的每一個字(詞語)。從數學或從機器學習的角度來看,語言模型是對詞語序列的概率相關性分布的建模,即利用已經說過的語句(語句可以視為數學中的向量)作為輸入條件,預測下一個時刻不同語句甚至語言集合出現的概率分布。
GPT 3.5 本身很難理解人類不同類型指令中蘊含的不同意圖,也很難判斷生成內容是否是高質量的結果。為了讓 GPT 3.5 初步具備理解指令的意圖,首先會在數據集中隨機抽取問題,由人類標注人員,給出高質量答案,然後用這些人工標注好的數據來微調 GPT-3.5 模型(獲得 SFT 模型,Supervised Fine-Tuning)。
第二階段:人類老師引導文字接龍的方向
為了讓文字接龍符合人類偏好,在 ChatGPT 學習文字接龍的過程中,人類老師的引導非常重要。主要通過人工標注訓練數據(約 33K 個數據),來訓練回報模型。在數據集中隨機抽取問題,使用第一階段生成的模型,對於每個問題,生成多個不同的回答。人類標注者對這些結果綜合考慮給出排名順序。
這一過程類似於教練或老師輔導。人類老師可以透過指定主題或詞彙來引導 ChatGPT 生成相關的語句。
第三階段:訓練獎勵模型,模仿人類喜好
在 ChatGPT 學習的過程中,它可以透過模仿人類老師的喜好來進一步提高自己的語言生成能力。透過瞭解人類老師喜好的主題、詞彙、表達方式等,ChatGPT 可以生成更加符合人類期望和偏好的語句。使用第二階段的排序結果數據來訓練獎勵模型。對多個排序結果,兩兩組合,形成多個訓練數據對。RM 模型接受一個輸入,給出評價回答質量的分數。這樣,對於一對訓練數據,調節參數使得高質量回答的打分比低質量的打分要高。
透過這種方式學習,ChatGPT 可以更好地理解不同語境下的語言使用方式,進一步提高自己的生成能力。
第四章節:用增強式學習向模擬老師學習
在 ChatGPT 學習的最後階段,這一階段利用上一階段訓練好的獎勵模型,靠獎勵打分來更新預訓練模型參數。在數據集中隨機抽取問題,使用 PPO(Proximal Policy Optimization,近端策略優化)模型生成回答,並用上一階段訓練好的獎勵模型(模擬老師)給出質量分數。把回報分數依次傳遞,由此產生策略梯度,通過強化學習的方式以更新 PPO 模型參數。
白話來說,它透過增強式學習的方式向模擬人類老師學習。增強式學習是一種
透過獎勵和懲罰來指導機器學習的方法。當 ChatGPT 生成符合人類期望的語句時,它可以得到獎勵,從而學會更好地生成語句;而當 ChatGPT 生成不符合期望的語句時,它可以受到懲罰,從而找到更好的生成方式。透過這種方式學習,ChatGPT 可以不斷優化自己的生成能力,生成更加符合人類期望的語句。
未來的 ChatGPT:連接網路的 GPT
可以預期的是,就像現在 Bing 的 AI,未來 ChatGPT 能夠與網際網路上的資料進行連接,從而實現更加豐富和多樣化的即時資料,而不再是停留在 2021 年,那時候的 ChatGPT 模型將具有更加強大和靈活的對話和自然語言處理功能。這些功能將有助於應對更加複雜和多樣化的自然語言處理任務,並且可以為使用者提供更加智能、人性化的服務。