生成式 AI 的技術門檻,護城河並非不可逾越
在過去,人們普遍認為只有少數人能夠訓練大型語言模型,原因在於計算資源的限制、GPU 和顯卡的高成本以及算力需求的快速增長。但隨著開源的快速發展,實際上幾乎所有人都可以參與和探索 LLM 的生成式應用開發,真正的護城河會是什麼?


在過去,人們普遍認為只有少數人能夠訓練大型語言模型,原因在於計算資源的限制、GPU 和顯卡的高成本以及算力需求的快速增長。
例如,以 ChatGPT 為例,其訓練算力消耗約為 3640PF-days,相當於至少需要 7-8 個投資 30 億規模的資料中心來支撐運行。此外,訓練大型語言模型需要上萬顆昂貴的 GPU,一次模型訓練成本超過 1200 萬美元。這些晶片的限制使得過去普通人無法輕易獲得足夠的計算資源來訓練大型語言模型。(參考:真相殘酷,ChatGPT 的狂歡與中國無關,因為 AI 芯片差距二十年。)
隨著 AI 在開源上面的進展以及李宏毅老師的 窮人版 ChatGPT 教學,我們可以發現實際上幾乎所有人都可以參與和探索 LLM 的生成式應用開發。
當潘多拉的盒子被 Meta 打開
Google 一直以來都跟 OpenAI 用一樣的策略,很小心翼翼地保護自己的發明,因為怕強大的 AI 被濫用。原先 LLM 的發展趨勢是將模型引入更多的參數(從 GPT-1 的 117M 到 GPT-3 的 175B),按照這個趨勢發展,遲早我們就會遇到運算資源的瓶頸,但 Meta 釋出的 LLaMA 改變了一切。
就像是潘多拉的盒子被打開之後一發不可收拾,LLM 開始百花齊放。
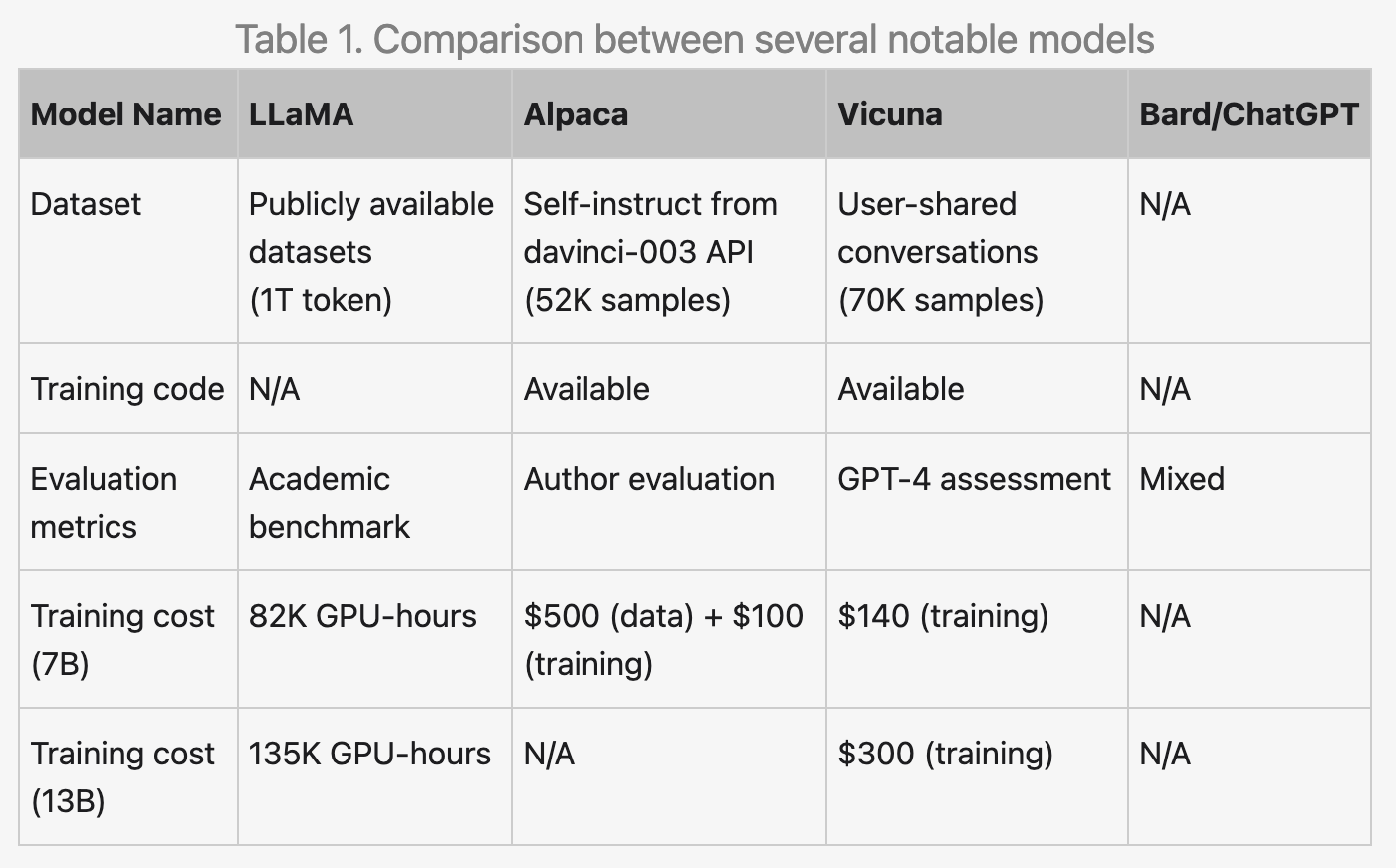
由 LLaMA 衍生出來的各種 ChatGPT 開源替代品
從 Google 洩露的內部信件也表示了這點,我們可以看到 Google 的一個研究員提到了過去這兩個月從 LLaMA 釋出後造成的 LLM 大爆發,讓 open source 的 LLM 發展速度遠超過大家的想像,比較知名的有這些模型:
- BLOOM: 由 BigScience 開發,是一個由世界各地的研究人員合作的項目。它是一個在文字和程式碼的大規模資料集上訓練出來的 1760 億個參數的模型(GPT-3 只有 1750 億個參數)。
- LLaMA(Language Model for Dialogue Applications)是由 Meta AI 開發的開源聊天機器人框架。它基於 Transformer 架構,並使用大規模的文字和程式碼資料集進行訓練。LLaMA 以其生成逼真且引人入勝的對話而聞名。
- Alpaca 是由斯坦福大學開發的另一個開源聊天機器人框架。它基於 LLaMA 框架,並使用人類生成的對話資料集進行訓練。Alpaca 以其學習和適應新對話的能力而聞名。
- Vicuna 是由加利福尼亞大學伯克利分校開發的開源聊天機器人。它基於 LLaMA 框架,並使用人類生成的對話資料集進行訓練。Vicuna 以其生成創造性和訊息豐富的文字的能力而聞名。
- OpenChatKit 是用於開發聊天機器人的開源工具包。它包含各種功能,如訓練、微調和內容監控。OpenChatKit 是開發人員想要建立自己的聊天機器人的良好選擇。
- Open Assistant:Open Assistant 是一個開源項目,旨在建立一個由 LAION 和世界各地的貢獻者運行的支持聊天的 GPT LLM。它是一個對話式的人工智慧,可以理解任務,與第三方系統互動,並動態地檢索訊息來實現。
LoRa 能更快地局部訓練模型
在開源社群中,我們見證到了 LLaMA 的巨大進展。
相對於 GPT-3,LLaMA 體積更小,並且不斷受到廣大社群的改進和縮小,以至於現在可以在家用 GPU 甚至手機上運行。Stanford 隨後釋出了 Alpaca,透過指導微調(Instruction Fine tuning)的方式,快速提升了小型 LLM 的能力,使其接近 ChatGPT 的水準。
LoRa 是一種可大幅減少訓練模型所需記憶體空間的技術,用於訓練穩定擴散模型的優化演演算法。Lora 能夠找到穩定擴散模型的最佳參數,從而產生更高質量的輸出。相比其他優化演演算法,Lora 還能更快地訓練穩定擴散模型。
最近的參數高效訓練(PEFT)技術(如 LoRA / LLaMA-Adapter)和低精度訓練(如 bitsandbytes 庫)的應用使得精調 LLM 變得非常廉價且有效,即使是對於非常大的模型,只需要少量的 GPU 和短時間的訓練。
從這個生態發展的路線我們可以看到現在的基本模型已經足夠好,搭配 LoRa 的局部訓練方式,並不是所有人都需要再投入到 LLM 的模型調校上面,關鍵還是在應用端的微調,如何更接觸使用者,並且解決實際的問題,讓應用可以遍地開花。
ChatGPT 有許多開源的替代品跟競爭對手,MidJourney 也不例外,在開源上面,現在 Stable Diffusion 的表現以及可以調整的細節,甚至已經超越 MidJourney,搭配各種 LoRa 讓 Stable Diffusion 穩定擴散模型成為生成高質量圖片和文字的強大工具。
我們原先認為困難的開放問題
Oops haven't tweeted too much recently; I'm mostly watching with interest the open source LLM ecosystem experiencing early signs of a cambrian explosion. Roughly speaking the story as of now:
— Andrej Karpathy (@karpathy) May 6, 2023
1. Pretraining LLM base models remains very expensive. Think: supercomputer + months.…
原先我們認為需要一段時間才可以被解決的問題以及研究方向:
- 在手機上運行 LLM:人們現在可以在 Pixel 6 手機上以每秒 5 個標記運行基礎模型。
- 可擴展的個人化 AI:你可以在筆記型電腦上在一個晚上對個人化 AI 進行微調。
- 模型會因為監管而限制能力:現在有整個網站充滿了沒有任何限制的藝術模型,而文字方面也不遠了。
- 多模態訓練不易:目前最先進的多模態科學問答系統在一小時內訓練完成。
- 模型的處理速度與能力:雖然 Google 的模型在質量上仍然稍占優勢,但差距正在以驚人的速度縮小。開源模型更快、更可自定義、更具隱私性,且在性價比上更具優勢。
- 私有性與可定製性:開源模型在私有性和可定製性方面比 Google 的模型更強大。
- 付費的模型有更多限制:當有免費、無限制的替代品在質量上可比擬時,人們不會願意為受限制的模型付費。Google 需要考慮其真正的價值所在。
- 小模型做到巨型模型一樣的效果:長期而言,能夠快速迭代的模型才是最好的模型。現在我們已經知道在小於 200 億參數的範疇內有什麼可能性,因此應該將小型變體模型視為重點的發展方向。
這一趨勢至今仍在持續發展,不出幾個月的時間,人人都可以在家中的電腦和手機上運行與 ChatGPT 相媲美的 LLM,而且還是免費的。
開源消弭了我們原先認為的技術壁壘
即便一開始是落後的,從 Google I/O 2023 我們還是可以看到 Google 在短時間迎頭趕上並且超越,推出的時候直接就是面向十億的上網人口,意味著現在只要有足夠的算力,任何人都可以短時間內推出大型語言模型的應用。
Meta 在這場 AI 戰爭中有望成為最終的贏家,是因為他們在釋出 LLaMA 時採取了一個關鍵策略。這個策略是將 LLaMA 標示為僅供「研究」使用,這使得 Meta 能夠獨家受益於這一開源成果。
儘管有許多未經授權流傳的 LLaMA 版本,但開源社群對此並未加以管制,而 Meta 也不積極追究這些個人的行為。然而,對於企業而言,使用 LLaMA 進行商業用途則存在著極高的風險,有可能會被 Meta 提起訴訟。因此,所有公司都無法使用 LLaMA、Alpaca、Vicuna 或其他由 LLaMA 衍生出來的生態系統。
然而,Meta 卻可以自由地將所有這些開源成果納入其內部產品或研究中,這給予他們巨大的競爭優勢。這個「研究專用」的條款成為 Meta 的關鍵,如果他們能夠善加利用,有潛力在這場 AI 戰爭中以彎道超車的方式脫穎而出,最終成為最大的贏家。Meta 擁有將開源成果整合到內部產品和研究中的自由度,這將為他們帶來獨特的競爭優勢,並使他們能夠領先於其他競爭對手。因此,Meta 在這場 AI 戰爭中具有極大的潛力,有望成為主導力量。
擁抱開源和擁抱變化,接近客戶並解決問題
我們應該積極擁抱開源,特別是在區塊鏈領域,因為這將扮演著相當關鍵的角色。開源模式將帶來更多的創新內容,同時也需要透過區塊鏈來管理這些開源資源。
然而,真正的關鍵在於應用端的微調。我們終於意識到,再次訓練 LLM 的必要性並不如以前迫切。這是因為 LoRA 技術的出現以及開源社群的努力,讓應用程式在各個領域中蓬勃發展。
在這個時代,真正重要的是我們與客戶的緊密聯繫,以瞭解並解決他們所面臨的問題。我們需要積極擁抱開源社群的貢獻,並與他們合作創造更多的價值。同時,我們也必須擁抱變化,因為這是不可避免的。只有透過積極適應變化,我們才能保持競爭力,為客戶提供最佳的解決方案。
因此,我們應該持續加強與客戶的溝通與互動,並與開源社群建立緊密的合作關係。同時,我們也應該敏銳地洞察變化,並隨時調整我們的策略和方法,以確保我們能夠在不斷變化的環境中繼續繁榮發展。
人工智慧與區塊鏈,將為我們打造更完美的 Web 3.0
隨著人工智慧(AI)的不斷發展,人們將對於 Web3 的價值有更加深入的認識。這是因為人們將意識到傳統的 Web2 網際網路所面臨的限制無法有效支撐各種應用的需求。這種情況類似於 1996 年某位主持人對 Bill Gates 對於網際網路潛力的嘲笑,以及 2002 年 Jay Leno 對亞馬遜無法盈利的嘲弄。如今,事實證明他們兩位才是對的。
Web3 將推動 AI 的發展以及元宇宙的建設,同時也將有助於實現物聯網的價值和資料閉環。由於物聯網一直無法發揮其潛力,並且在發展方面遠遠落後於移動網際網路,這種現象並非偶然。
Web3 與 Web2 最大的區別在於資料儲存的方式。在 Web3 中,資料不再僅限於單一公司的資料庫中,而是儲存在一個公共資料庫-網際網路上。這將對商業模式帶來重大的正向變革。相對於 Web1 和 Web2,Web3 所能釋放的經濟增量遠遠超越前者:首先,Web3 擁有全網通用的身份識別機制(Web2 缺乏協定級的身份層面);第二,Web3 內建了經濟支付系統。
當價值能夠像訊息一樣在網際網路上自由流動時,才能稱其為真正的網際網路。因此,Web3 在改變商業模式、釋放經濟增量方面具有巨大的潛力。