ChatDev:AI 代理組成的軟體開發團隊


近年來,AI 領域的突破令人矚目。布朗大學與中國多所大學合作的一項新研究,展示了一個由 GPT-3.5 驅動的「虛擬科技軟體公司」— ChatDev。這間公司不僅以驚人的效率和低成本開發軟體,還利用一種稱為「思考指令機制(Thought Instruction Mechanism)」的方法來協調各個 AI 角色。
該研究的主要目標是探索 GPT-3.5 是否能在沒有提前訓練的情況下,完成科技軟體公司開發軟體的工作。
實驗過程
ChatDev 按照傳統的瀑布式開發流程(Waterfall Model)被劃分為四個主要階段:設計、開發軟體、測試和維護。每個 AI 角色,如「CEO」、「CTO」、「程式設計師」和「測試工程師」,在不同的階段執行各自的任務。
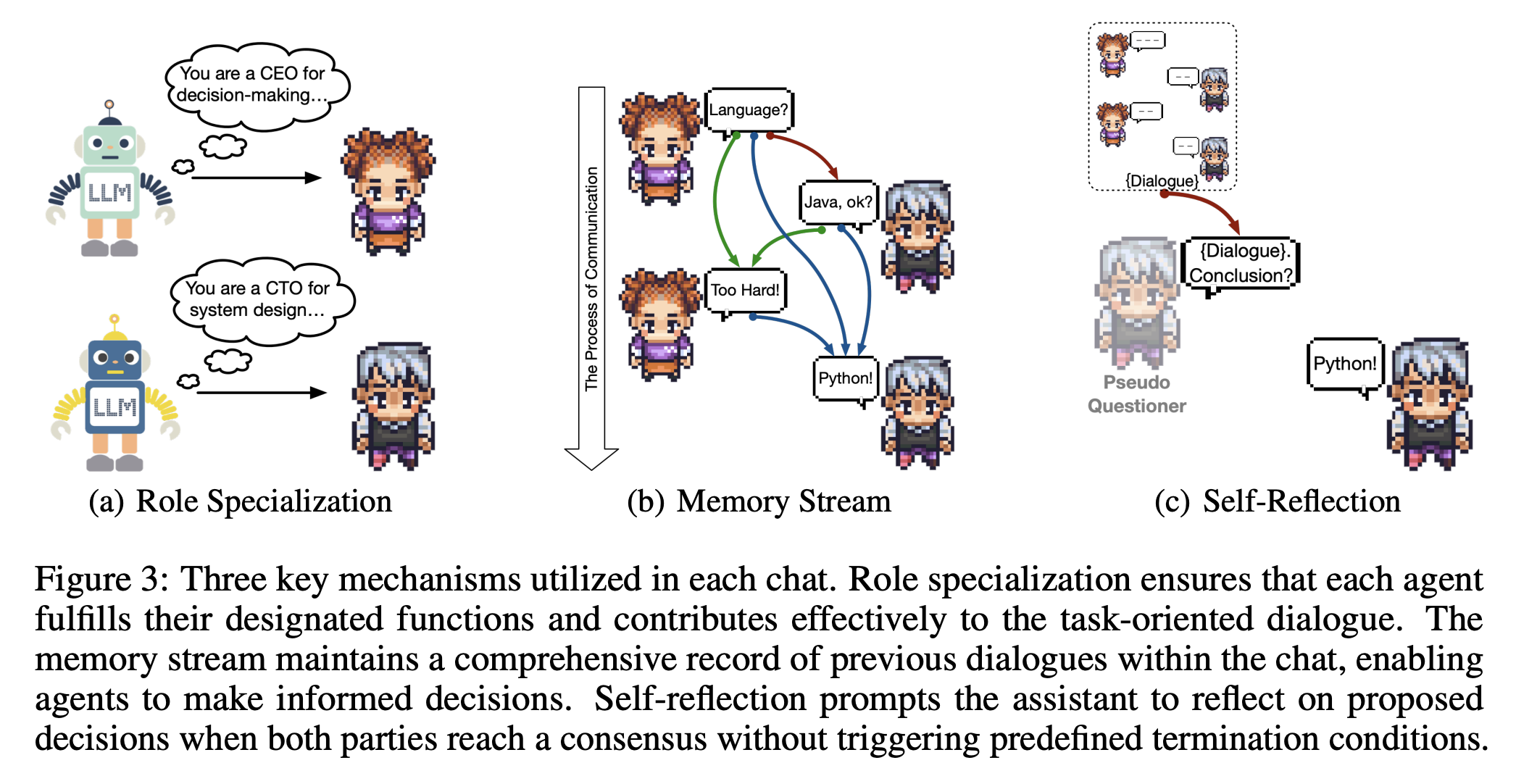
思考指令機制
論文中提到,思考指令機制(Thought Instruction Mechanism)是有助於減少所謂 "code hallucinations" ,實現成功軟體開發的關鍵。
一個實際例子可以更好地解釋這個機制。假設 ChatDev 被委託開發一個簡單的計算機應用程式:
- 設計階段: CEO 和 CTO 討論計算機應用程式應具備哪些功能(加、減、乘、除等)。
- 思考指令: CTO 給程式設計師一個明確的指示,例如:"請實現一個具有基本四則運算功能的計算機界面。"
- 開發階段: 程式設計師根據 CTO 的指示開始編寫代碼。
- 測試階段: 測試工程師運行程式,尋找錯誤或漏洞。
- 維護階段: 根據用戶反饋進行必要的更新和修復。
這個機制不僅使程式碼生成更為準確,促進了 AI 角色之間的有效協作。
實驗結果
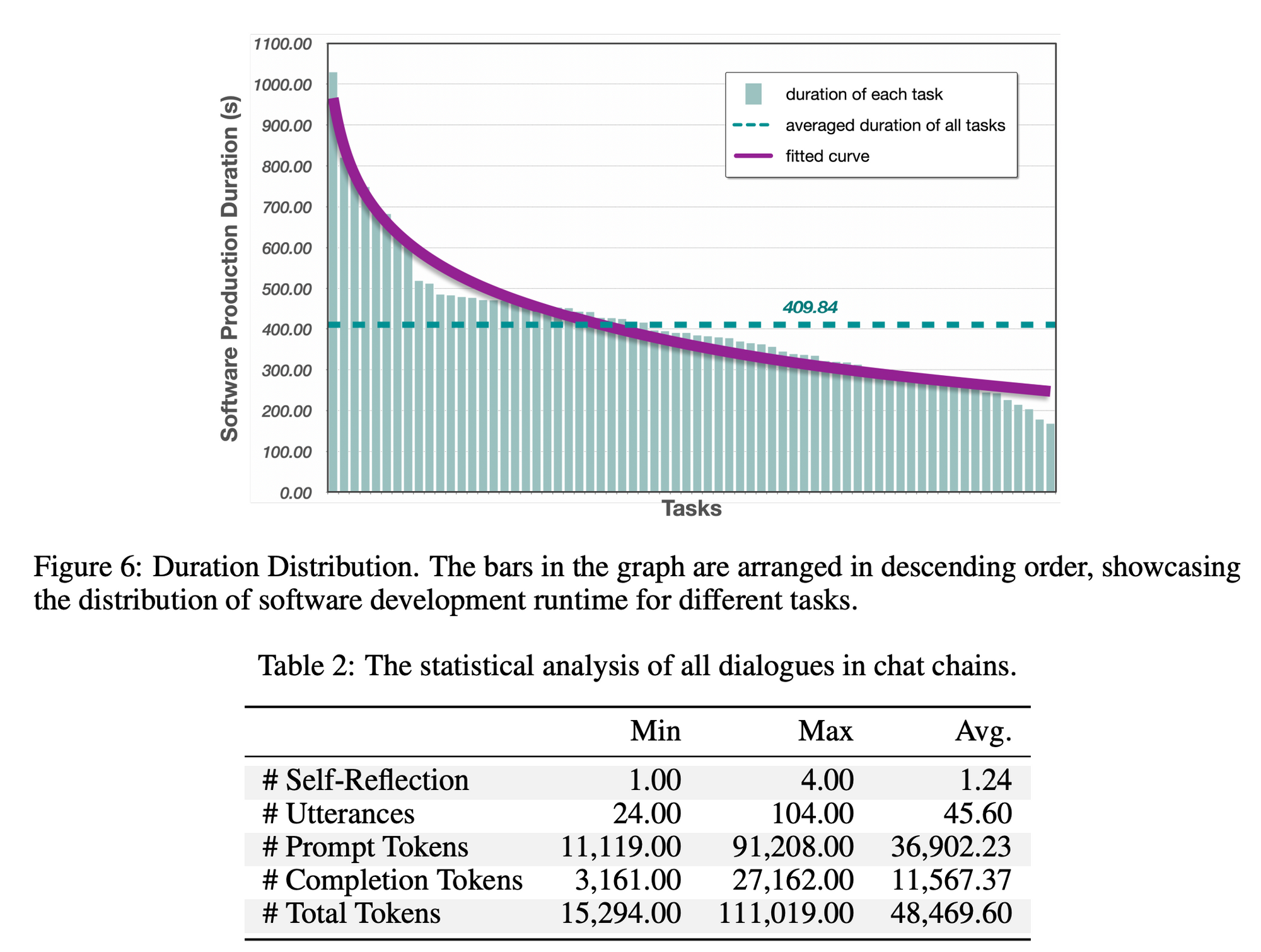
- 效率與成本: 有 86.66% 的開發軟體是完美的,平均只需 7 分鐘和 1 美元的成本。
- 自我修正: 程式設計師之間的對話發現,有將近 20 種程式漏洞被他們自己修改好了。
局限性和實驗限制:
儘管實驗結果優異,但仍有局限性,如生成結果的隨機性,以及程式碼和軟體需求的複雜性限制。
- 程式碼長度限制:由於 API 的令牌長度限制,生成的程式碼不能過長。這限制了 ChatDev 能夠處理的軟體複雜性。
- 外部依賴問題:在一些失敗的案例中,外部依賴(如庫或框架)的問題是一個主要因素。
- 缺乏高度專門化的知識:目前的模型可能不適合處理需要高度專門化或領域特定知識的任務。
- 人工干預需求:雖然模型可以自動生成程式碼和文件,但仍然需要人工審查和測試以確保質量。
- 輸出的隨機性: 生成輸出中固有的隨機性,即使大語言模型的溫度參數設定為非常低的值。
- 約 13.33% 的軟體遇到了執行失敗,這些失敗主要歸因於兩個因素:
(1)Token 長度限制:在 50% 的失敗案例中,失敗的原因是應用程式介面的 Token 長度限制,導致無法獲得完整的原始碼。
(2) 外部依賴性問題: 其餘 50% 的失敗案例主要受外部依賴性問題的影響,如依賴性不可用或版本不正確。
未來進步的空間:
- 提高代碼質量:透過更先進的機制,如更精確的思考指令或更高級的程式碼審查,來提高生成程式碼的質量。
- 擴展功能和複雜性:隨著技術的進步,ChatDev 可能會能夠處理更複雜和多功能的軟體開發任務。
- 集成更多外部資源:能夠更好地處理和整合外部依賴和庫,以擴展其應用範圍
- 自動化測試和維護:進一步自動化測試和維護流程,以減少人工乾預的需求。
- 領域特定模型訓練:訓練更專門化的模型,以處理特定領域或行業的軟體開發需求。
結論
ChatDev 實驗不僅展示了 GPT-3.5 在軟體開發方面的潛力,也為未來 AI 驅動的協作模式鋪平了道路。然而,該領域仍需進一步研究以克服現有的限制。
這讓我想起了之前的 MetaGPT,我認為這兩個 Repo 都是基於 AutoGPT 之上持續發展,以實際上的程式碼與實驗結果帶給我們更多對於 AI 代理人的想象空間: